

Dedupe in Excel: find and remove duplicate values
Deduplication of data is a common problem in Excel. Excel itself offers a practical function to perform simple deduplication, but this deduplication is definitive and difficult to check.
Our Excel experts are often called in to help with the deduplication of complex files, for example when multiple sources have to be combined.
Simple deduplication
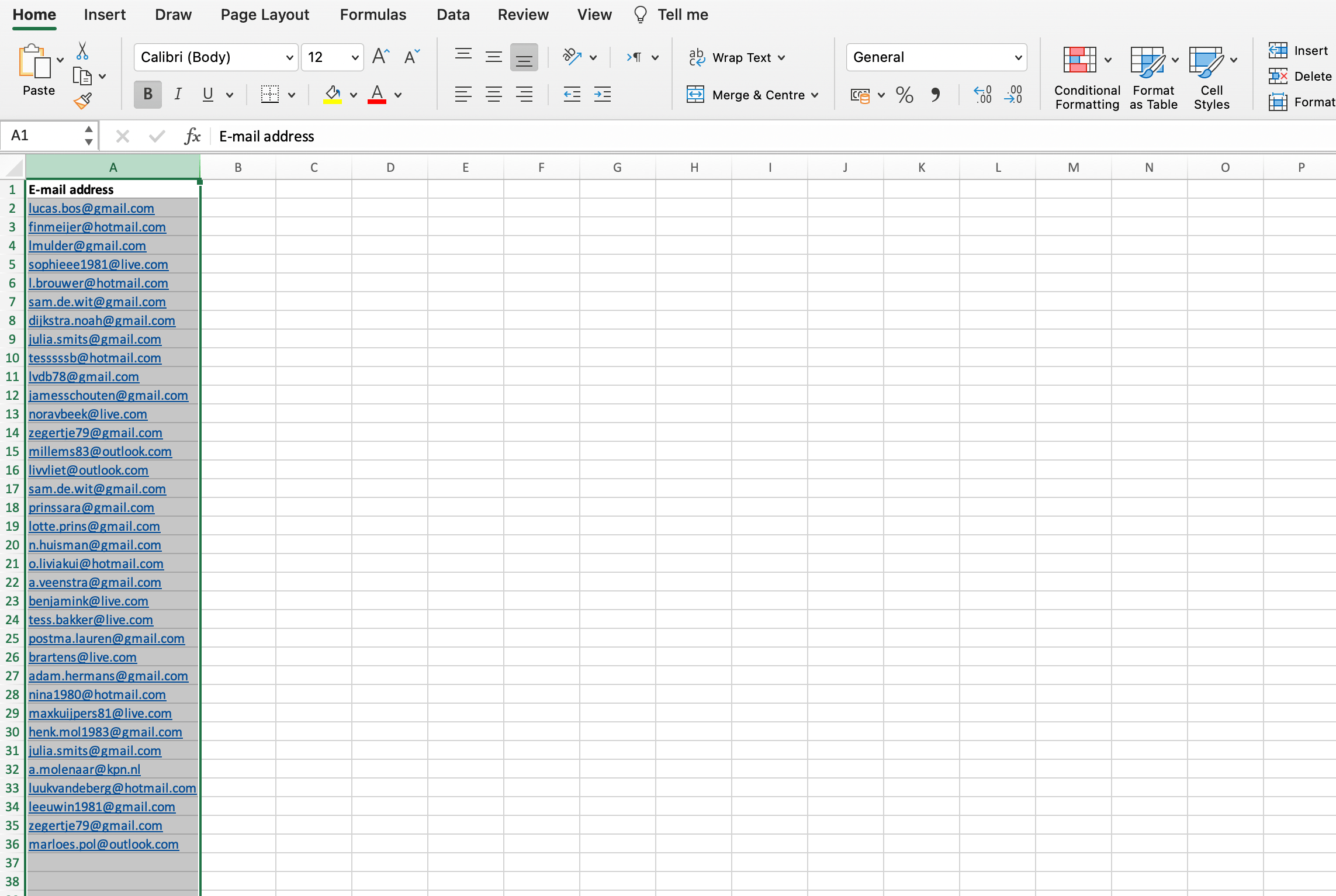
Excel itself offers excellent tools for simple deduplication. For example, if you have a list of email addresses, you can easily let Excel find and remove the duplicate values.
Find duplicate values
Select the area in which you want Excel to search for duplicate values:
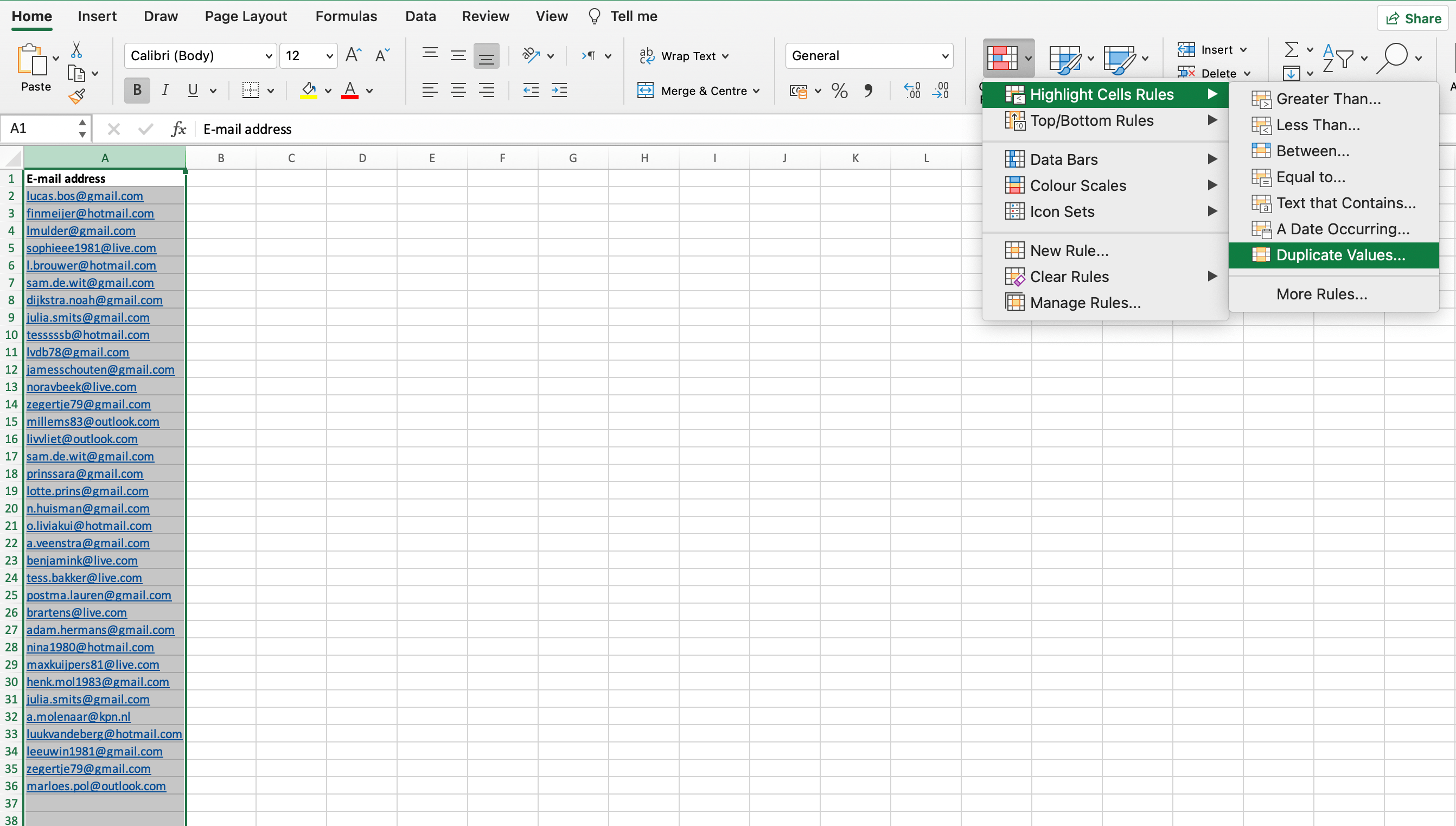
In your main menu, click Home > Highlight Cells Rules > Duplicate Values:
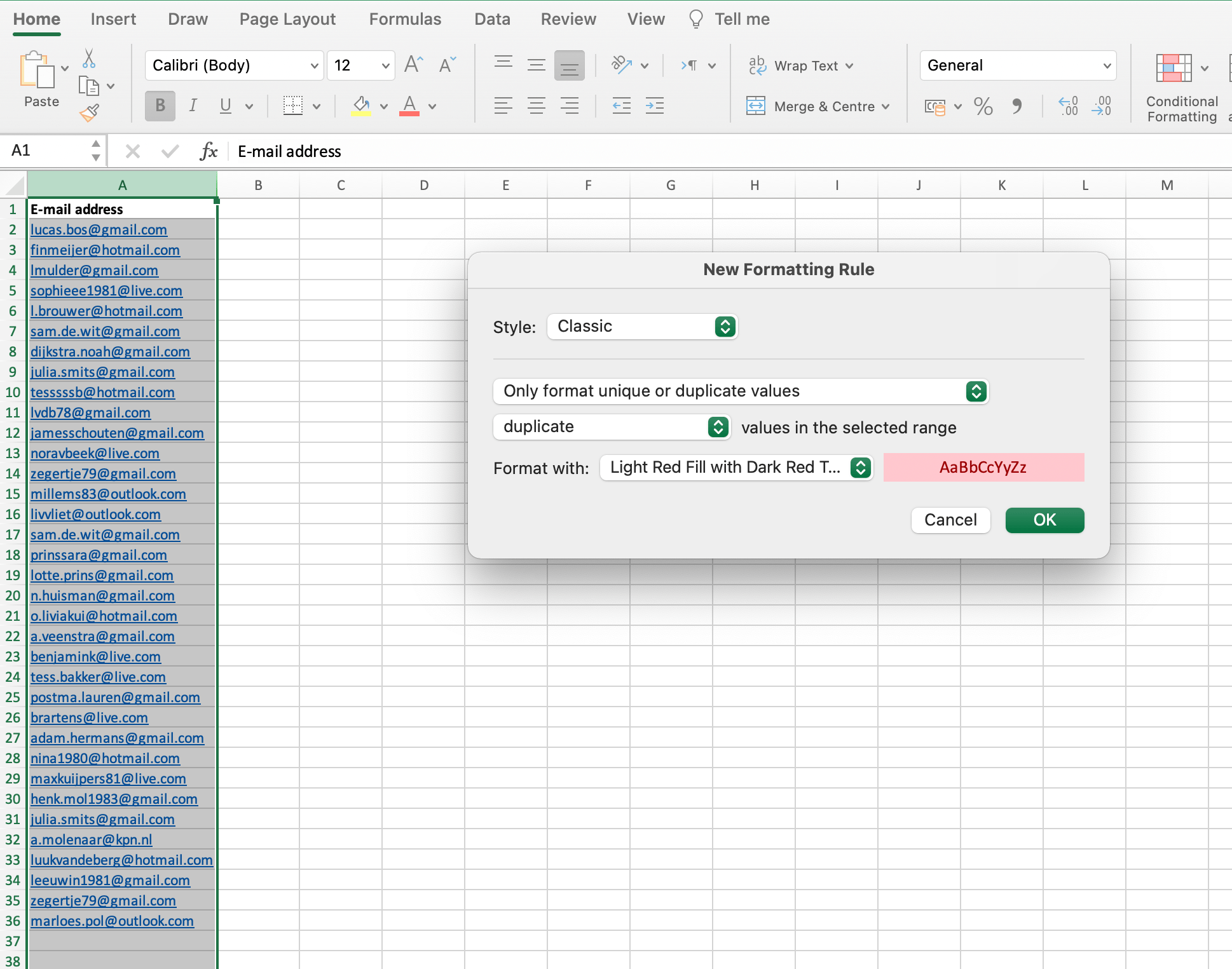
Click ‘OK’ in the pop-up window:
As a result, Excel shows all values that occur more than 1 time.
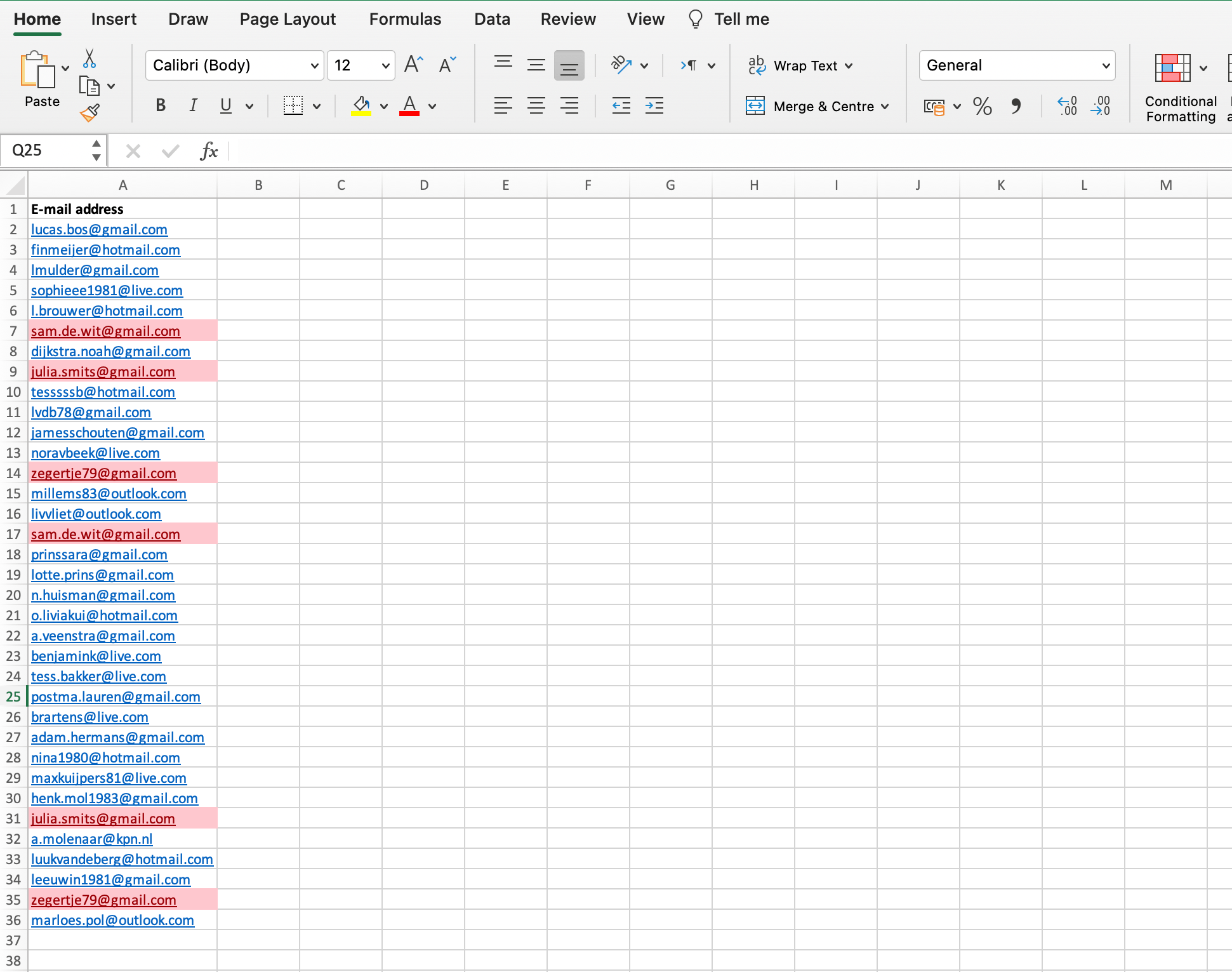
Remove duplicate values
To remove the duplicate values, select the relevant column again and click Data > Remove Duplicates:
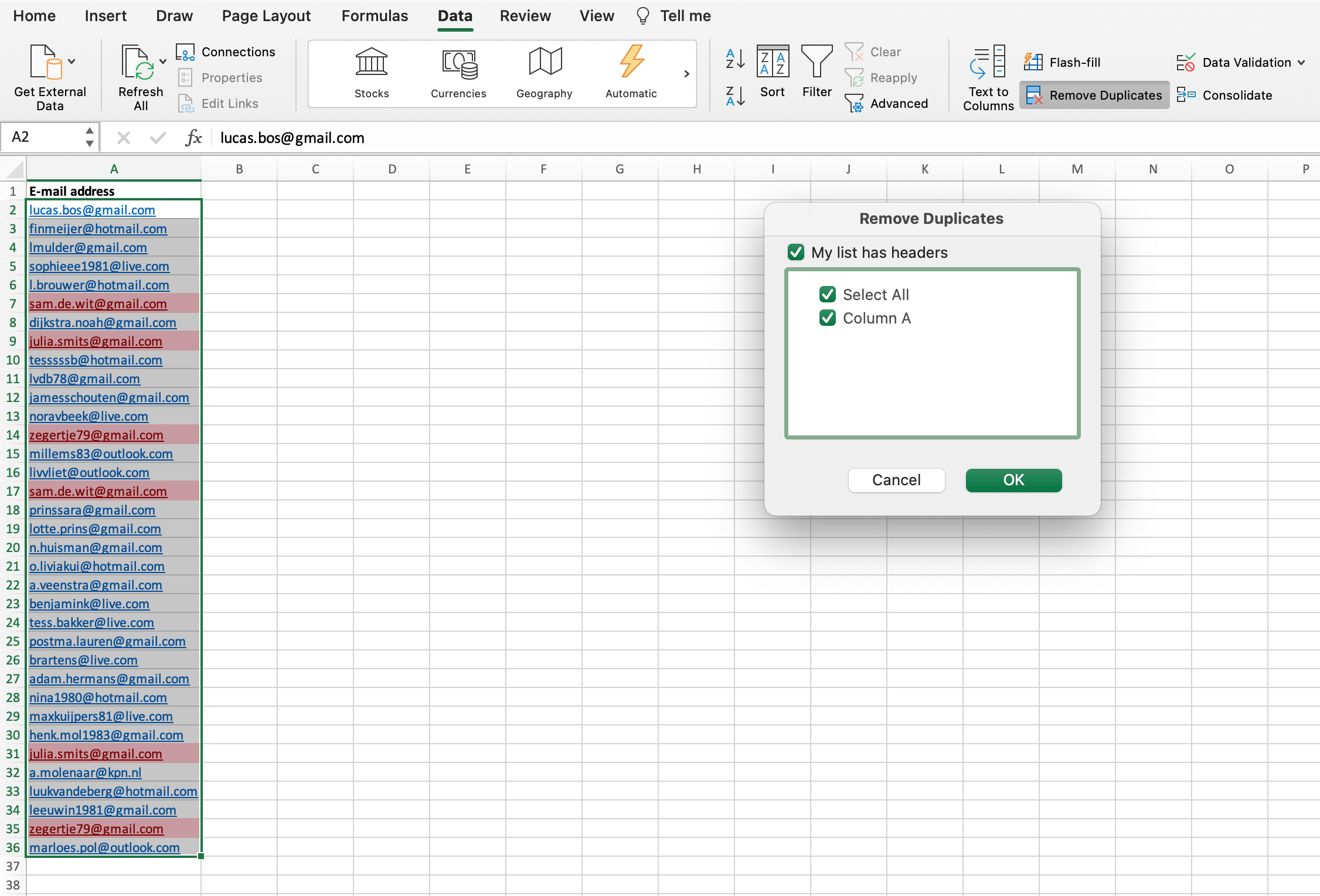
As soon as you click ‘OK’ in the dialog box, Excel removes all duplicate data (so a unique value always remains). In the pop-up screen you can see exactly how many entries have been removed and how many are left.
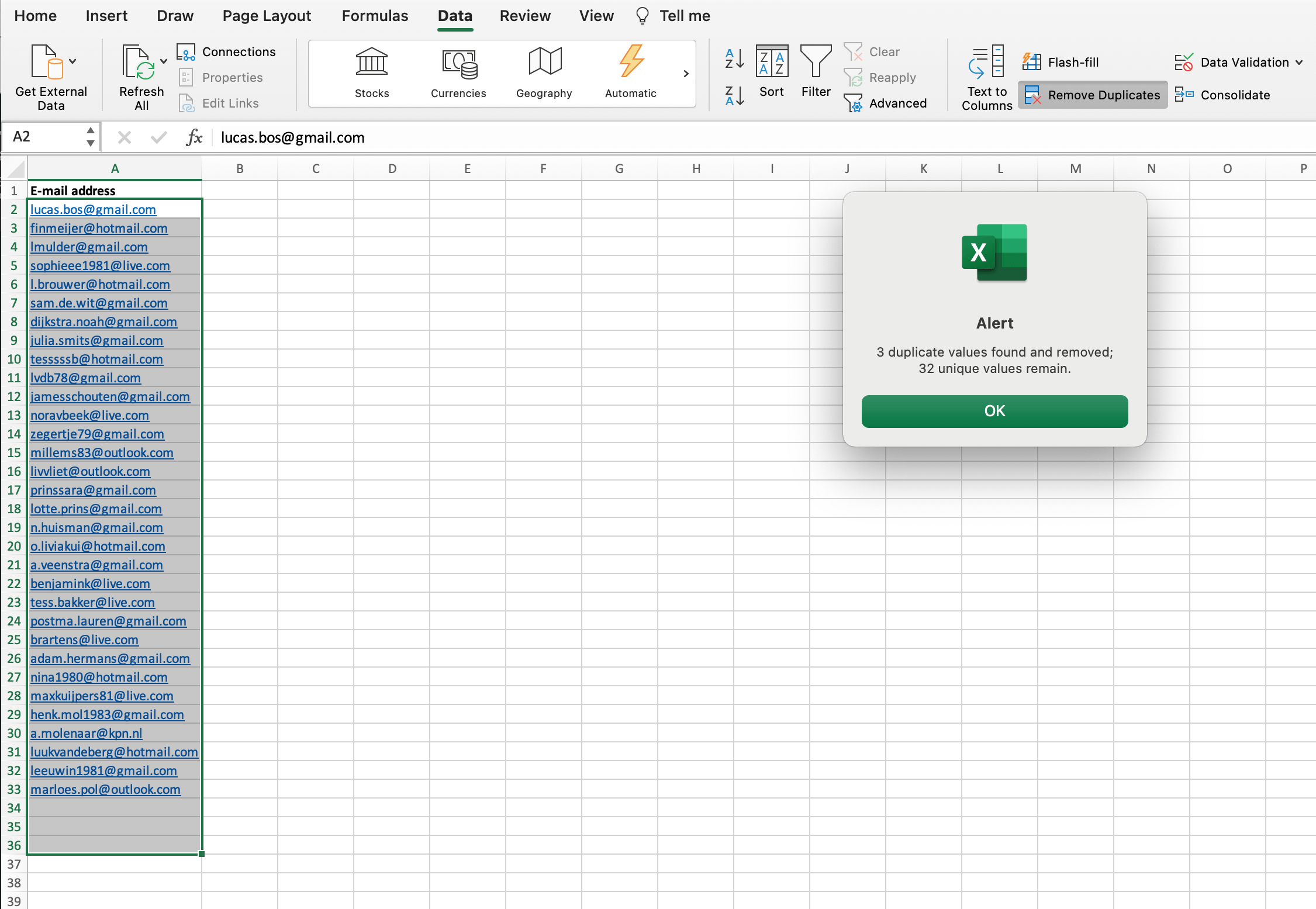
N.B. You don’t have to go through the steps of finding and highlighting the duplicate values. You can also proceed to deduplication directly.
Complex deduplication
Have a look at the address file below. There are four columns:
- First Name
- Last name
- Date of birth
- E-mail address
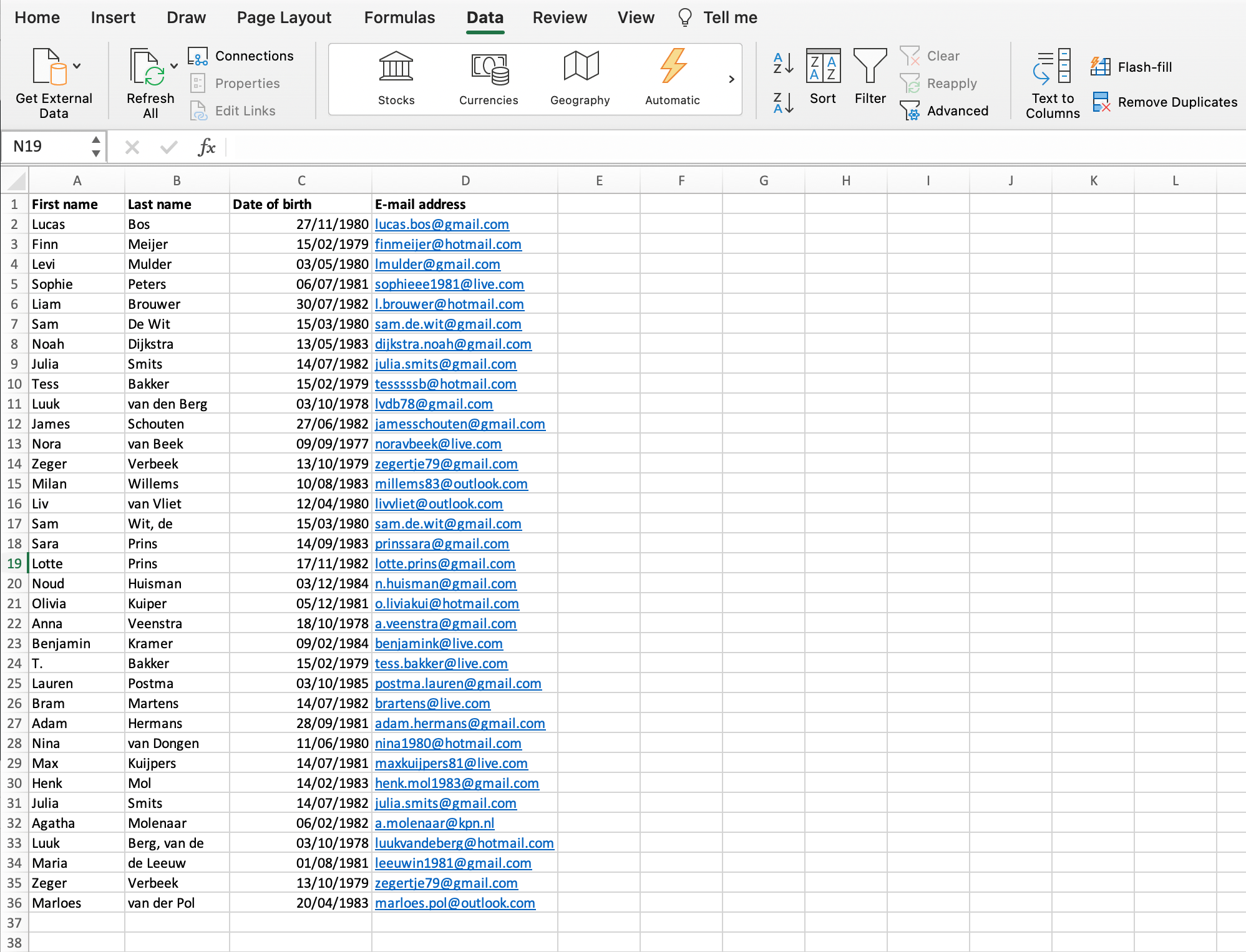
How do you dedupe such a file? Names and dates of birth can appear more than once, but do not necessarily point at a double entry. You could deduplicate based on a unique e-mail address, but what if several people in a household use the same e-mail address?
If we go through the same steps as in the first example, we find the following duplicate values:
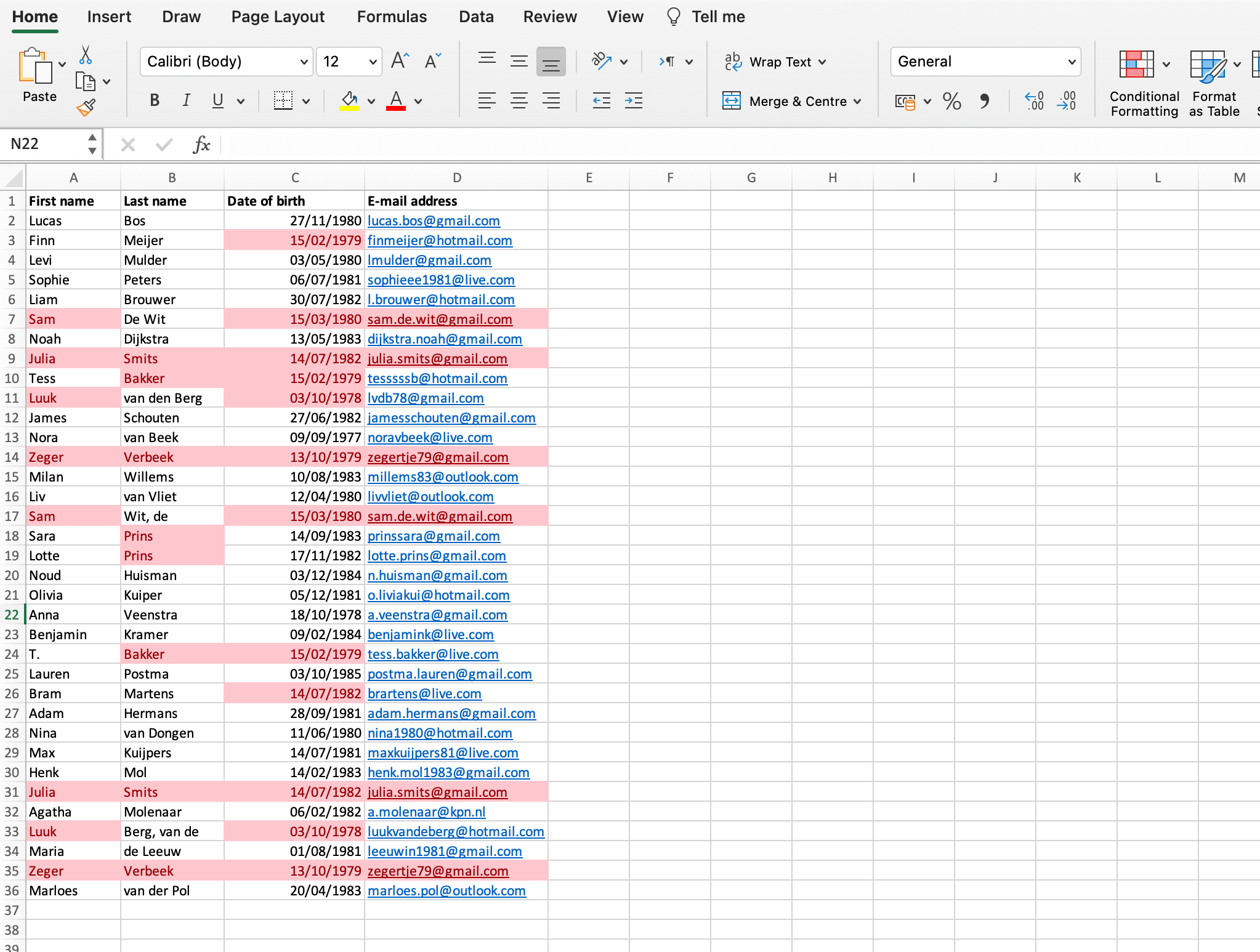
The problem of default deduplication in Excel
Now, if we ask Excel to dedupe in the same way as in our first example, only the duplicate values that appear in all four columns will disappear:
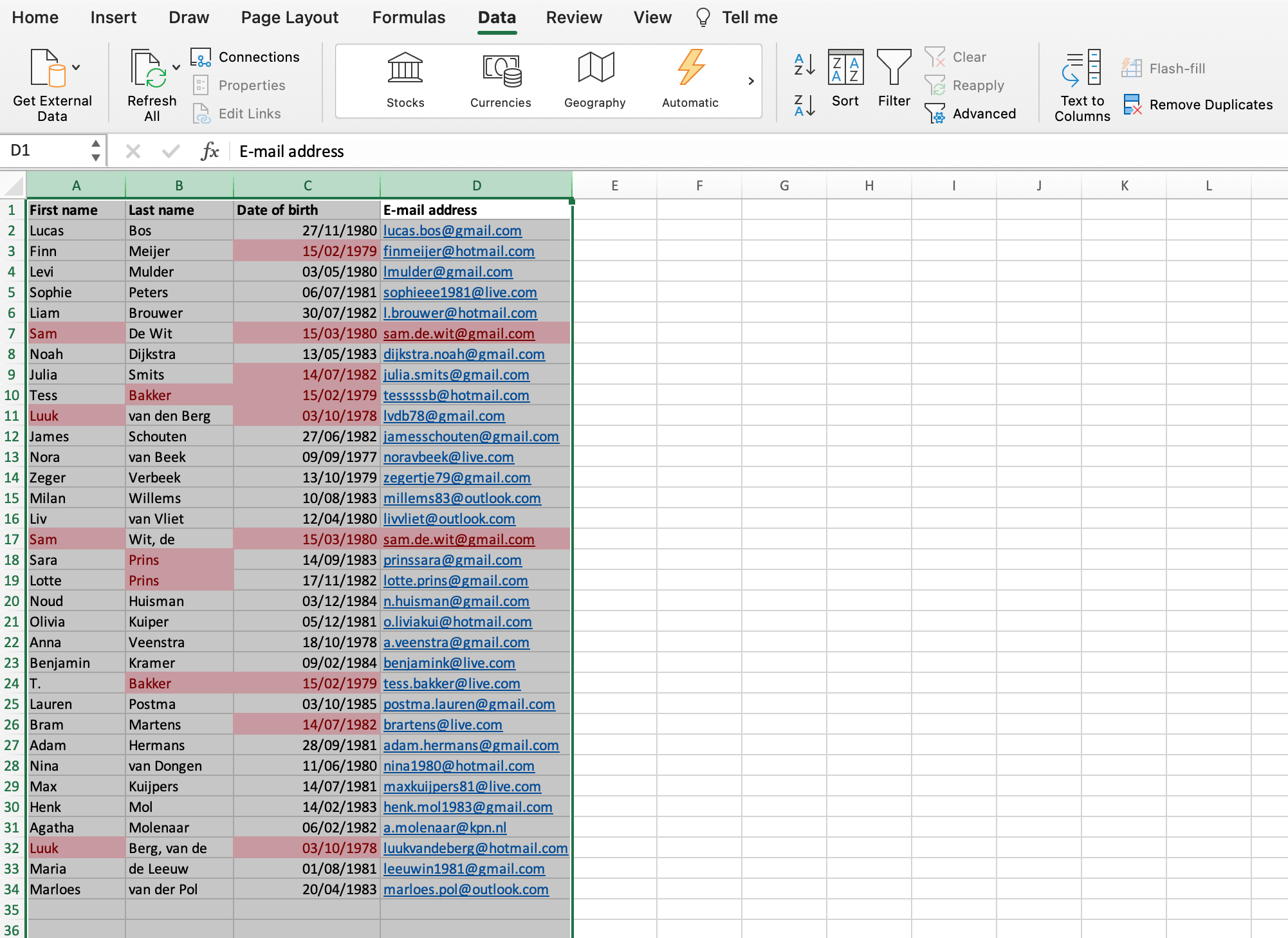
As you can see, Sam de Wit still appears twice in our database.
We can deduplicate a second round based on e-mail address, but in that case Tess Bakker will remain in our table twice, because she is registered with two different e-mail addresses:
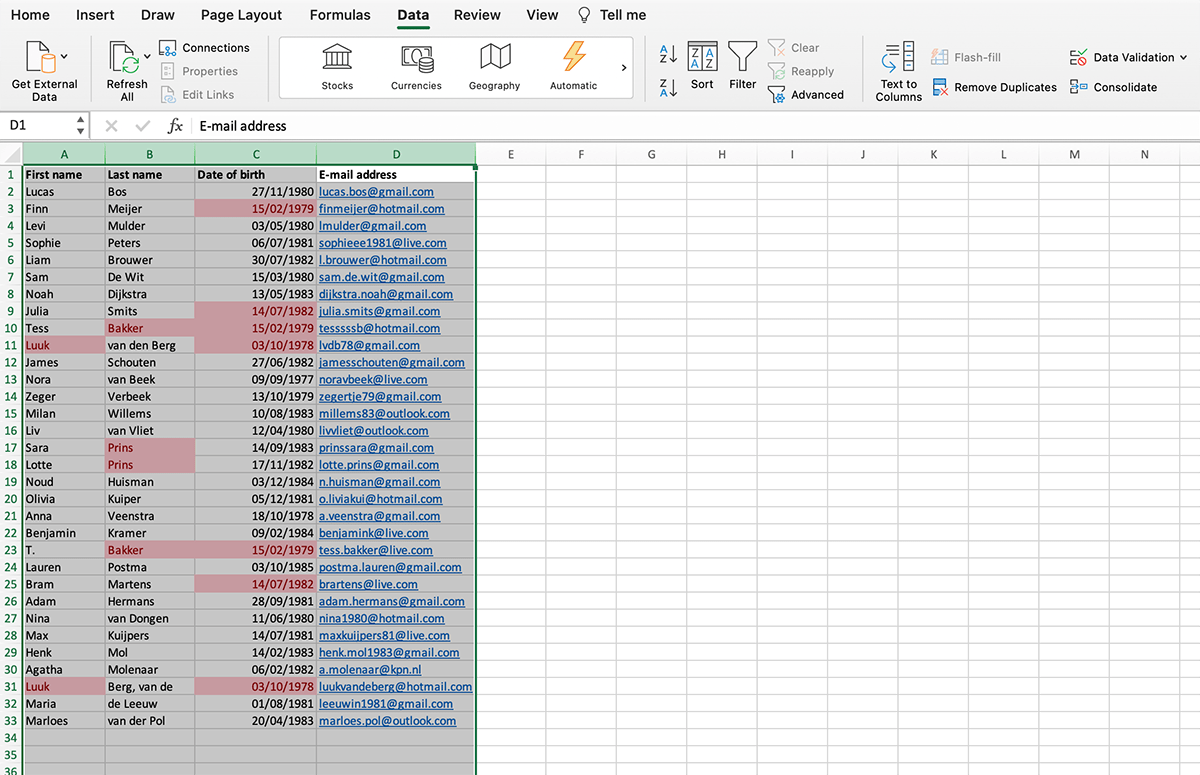
How do you deal with situations like these in the case of much larger files with much more data, or when multiple sources have to be combined?
Manual deduplication
Manual deduplication takes a little more time consuming to set up, but has several advantages. It allows you to keep (and add new data to) the original list on a first worksheet, while you generate the deduplicated list on a second worksheet. This way you can always compare the result with the source data.
See example below.

The table above shows whether a given email address appears more than once and then assigns a unique sequence number to each unique appearance. Of course, various functions are required for this set-up.
Functions
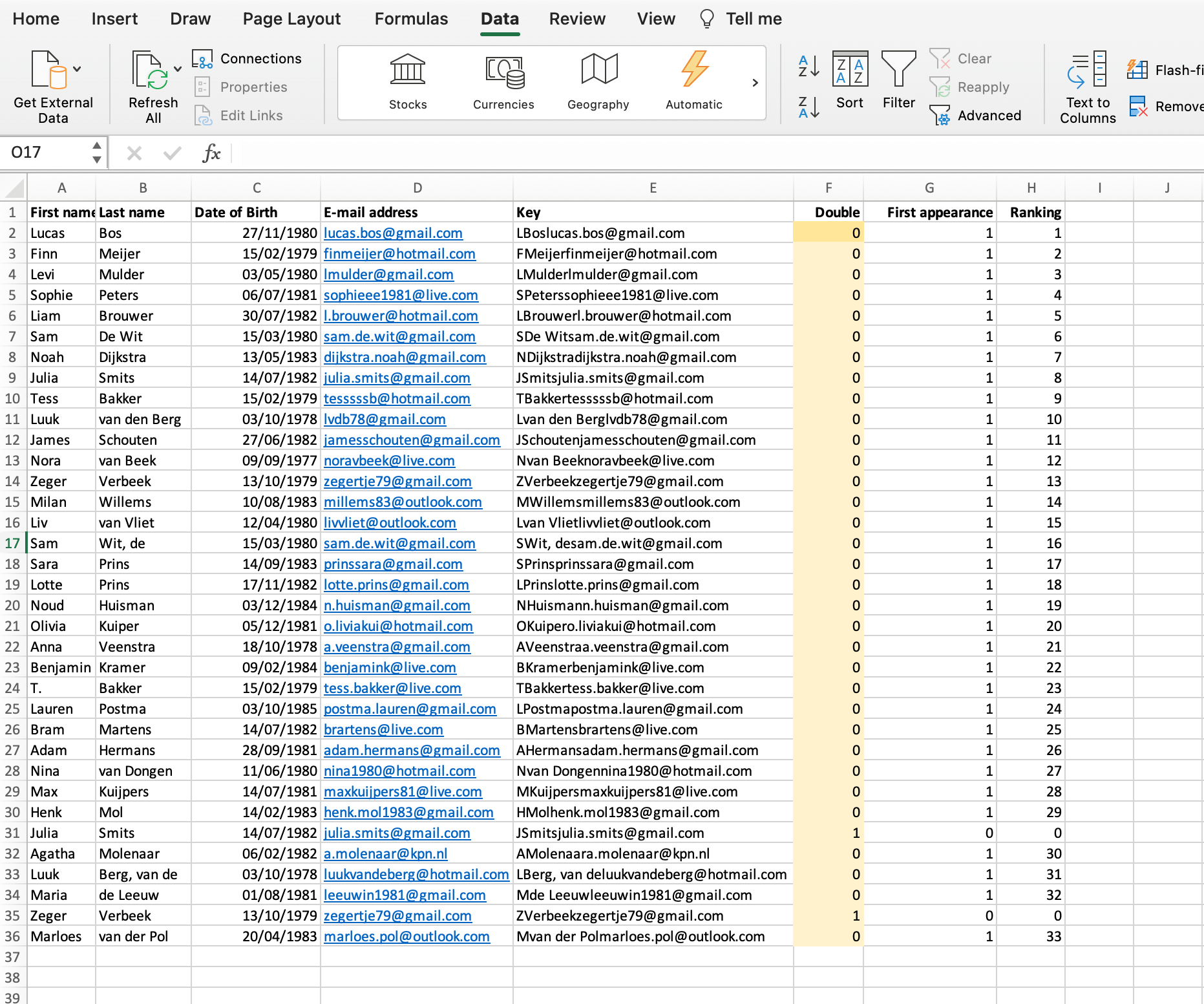
In column E (Double), we use the COUNTIF function to determine whether the email address in column D has already occurred in the range above. For example, cell E16 says: =COUNTIF(D$2:D15;D16). The result of this is 0.
In column F (First appearance) we use the IF function to check whether it is the first appearance of this email address or not. Cell F16 contains: =IF(E16=0;1;0). The result of this is 1.
Finally, we give each unique e-mail address a serial number in column G (Ranking). We do this with a combination of the IF function and the SUM function. Cell G16 contains: =IF(F16=1;SUM(F$2:F16);0). The result of this is 15.
Result
In a second worksheet we then publish the list of unique e-mail addresses using the combination INDEX and MATCH.
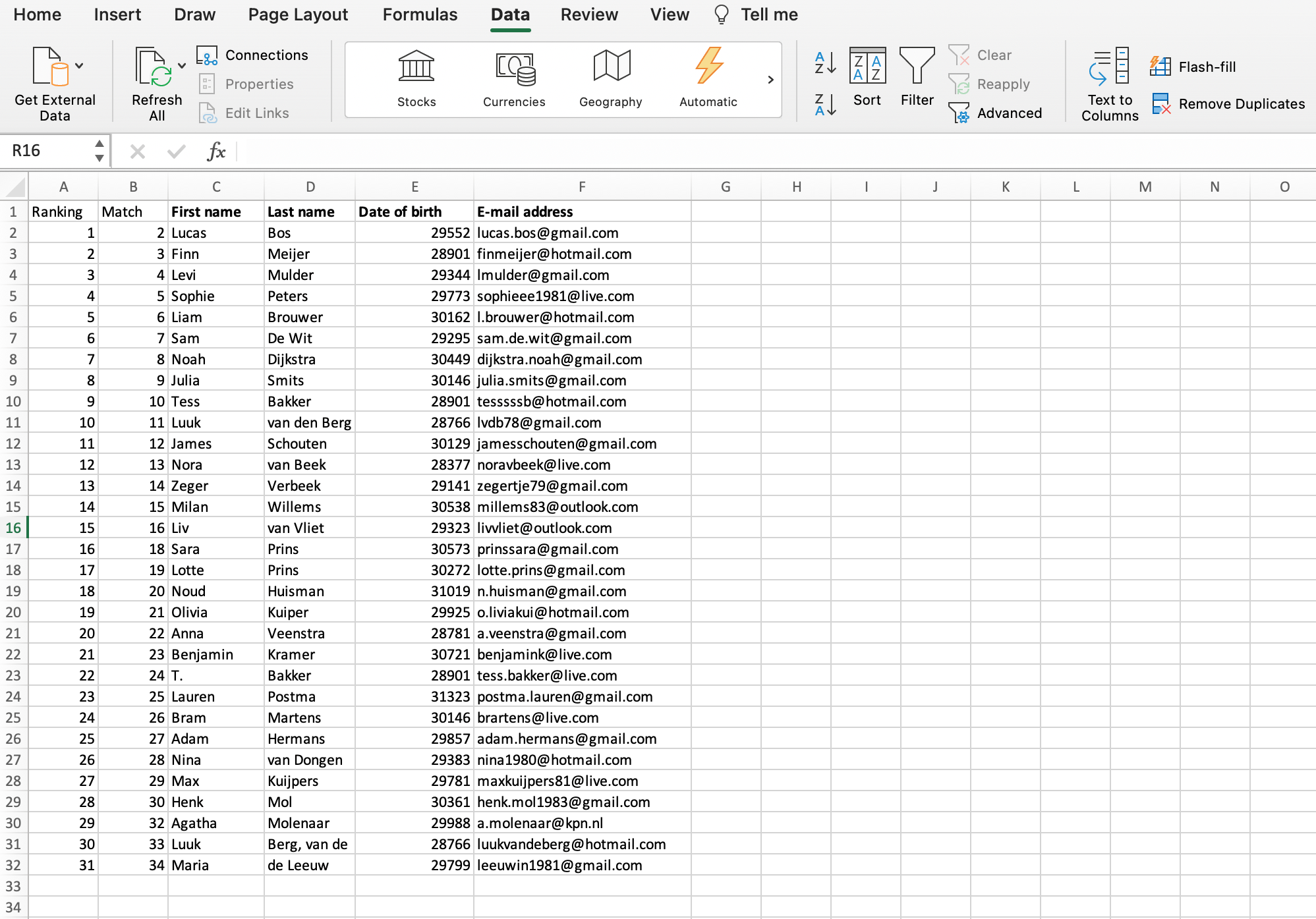
INDEX and MATCH
What does that look like in the case of this worksheet? In column B (Match) we use the MATCH function to find the sequence number in column A in the worksheet with the original data. For example, cell B16 says: =MATCH(A16;’Worksheet1′!G:G;0). The result of this match is 16, because sequence number 15 in the first worksheet matches row 16.
Next, we fill columns C through F with the data that can be found in the first worksheet on row 16 in the rows for First Name (column A), Last Name (column B), Date of Birth (column C) and Email Address (column D) using the INDEX function. In cells C16, D16, E16 and F16 it says:
C16: =INDEX(‘Worksheet1’!A:A;$B16)
D16: =INDEX(‘Worksheet1’!B:B;$B16)
E16: =INDEX(‘Worksheet1’!C:C;$B16)
F16: =INDEX(‘Worksheet1’!D:D;$B16)
Advantage
The advantage of this method is that you can hold on to the worksheet with the original data and add new data to it at any time. To complete the list of unique addresses on the second worksheet, you only need to expand the formula range.
Deduplication is a custom job
The examples above are quite simple, but in reality deduplication assignments are often complex. For example, if you want to merge multiple databases or files, or if you want to dedupe based on more than one column. In that case you can work with a ‘key’ that merges (elements) of various columns.
Key
In the worksheet below we have made a combination in column E (Key) of the first letter of the first name, the last name and the e-mail address. Next, in column F, we look for keys that appear more than once.
Determining the key and conditions for deduplication can be a complicated process and there can be many different scenarios. That’s why complex deduplication is often a custom job. At PerfectXL we are happy to help you with deduplication issues. Contact us for advice, or to outsource the deduplication to us.